Slurm 基本概念
Slurm 是一个开源的集群资源管理及作业调度系统,在现今的超算上被广泛使用。 它可以管理 CPU、GPU、内存、带宽等多种资源,让用户能方便地运行各种并行程序。
本节介绍 Slurm 的基本概念,目的是帮助用户更好地理解和使用实验室集群。
tip
建议不太熟悉 Slurm 的用户直接阅读 Slurm 的用法部分,在必要时以本节的内容作为参考。
多核/多线程架构的术语
参考:
术语列表(详细说明见后文):
- BaseBoard:主板,也可用英文 motherboard
- LDom:Locality domain 或者 NUMA domain,在具体配置下可能等同于 BaseBoard 或 socket
- Socket/Core/Thread:插槽、核心、线程,是用于多核多线程架构的术语
- CPU:计算资源分配的单位,在具体配置下可能等同于 core 或 thread
术语解释
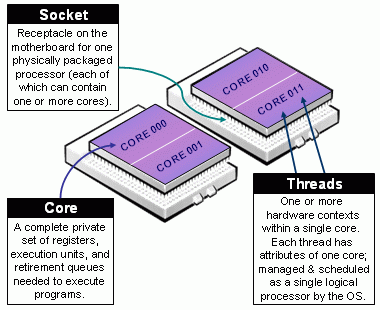
在 Slurm 中,用于描述硬件资源的术语和 Linux 系统的术语是一致的,我们平时用的 MPI 实现中的术语也一致。下图就是一个 baseboard(主板)。baseboard 上面可能有多个芯片插槽,记为 socket。一个 socket 可能包含多个物理核心,记为 core。一个核心上可能有多个硬件线程,记为 thread。
CPU 在 Slurm 中的含义和它在 Linux 系统上的含义稍微有一点区别。在 Linux 上,CPU 通常指的是总硬件线程数量;而在 Slurm 中,它是可调度的最小单位之一,随配置变化,可以是硬件线程数量,也可以只是物理核心数量。
习惯用语
在不引起歧义的情况下,我们平时描述硬件资源可能会采用不同术语。例如:
- 我们平时说的“处理器核”(processor core)可能指的是 core 或者 thread,视情况而定;
- “处理器”(processor)可能指的是 socket,也可能指 core,也可能是想表达 CPU 在 Slurm 中的含义;
- 我们所说的“核”,在测试程序时通常指的是表达最小可调度单位的 CPU;在说明硬件时通常指的是物理核心。
为了连贯性,本文档中的术语会尽量和 Slurm 保持一致。
以 Xeon E5-2620 v3 为例
在实验室集群上,使用 lscpu 命令可以看到有关处理器的详细信息。实验室集群的 Slurm 配置与 lscpu 看到的信息是完全对应的。下面截取部分信息作为例子:
$ lscpu
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Model name: Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
我们可以得到如下信息:
- 共有 2 sockets,也就是两块 Xeon E5-2620 v3;
- 每块 E5-2620 v3 包含 6 cores(物理核心);
- 每核心 2 threads(Intel 超线程);
- 该计算节点上共有 24 CPUs(也就是 24 threads);
- 该计算节点配置了 2 个 NUMA 节点,node0 对应编号
0-5,12-17的 CPU,它们实际上都属于第一个 socket;node1对应编号6-11,18-23的 CPU,它们实际上都属于第二个 socket。
同样,对于实验室集群的 Slurm 来说,一个 E5-2620 v3 的计算节点也就是 24 CPUs。用户在申请计算资源时,最小单位就是一个硬件线程,而不是物理核心。各个节点在 Slurm 中的配置可以用如下命令查看:
$ sinfo -lNe
用户在使用实验室集群时(事实上是所有将 CPU 配置为 thread 数量的集群),要注意根据自己的需求调整资源的数量、映射绑定等参数。例如,用户在需要超线程时可以直接按 CPU 数量申请,但在不需要超线程时,就要加上一些映射或绑定的参数来调整 Slurm 的资源分配。具体的做法见后续文档的 MPI 作业提交部分。
用 Slurm 命令指定资源
通过提交作业时给定的选项,我们可以精细地控制请求分配的资源数量。其中一个选项是 -B,它的作用是要 Slurm 为我们分配满足特定要求的节点,也就是对 sockets/cores/threads 的数量做一些限制。
-B, --extra-node-info=S[:C[:T]] Expands to:
--sockets-per-node=S number of sockets per node to allocate
--cores-per-socket=C number of cores per socket to allocate
--threads-per-core=T number of threads per core to allocate
each field can be 'min' or wildcard '*'
Total cpus requested = (Nodes) x (S x C x T)
例如,我们可以在脚本中要求 Slurm 仅为我们分配 sockets 和 cores 数量分别为 2 和 6 的节点,对于实验室集群来说就是包含 E5-2620 v3 的节点。
#SBATCH -B 2:6
绑定
使用 -B 选项代替其他选项时,要注意它会自动启用任务绑定。如果执行的程序不需要绑定,请参考文档中对提交作业的说明。
exclusive, oversubscribe
参考:
exclusive 的含义是独占,影响用户如何共享资源;oversubscribe 的含义是超额申请,决定一个资源能不能被多个作业同时使用。
实验室集群的分区默认不使用 exclusive,即非独占模式,多个用户可以共享同一节点。例如:两个用户都只申请 1 个 CPU 时,Slurm 可以分配给他们同一个节点 node08,此时两个用户都可以在 node08 上执行自己的程序。
同时,分区不使用 oversubscribe,每个 CPU 都不能同时被多个作业使用。实际上,实验室集群的配置是,同一个物理核心同一时间只能有一个作业。例如:一个节点有 24 CPUs,它最多能同时被 12 个用户使用,每个用户分配一个物理核心(包含 2 CPUs)。
如果想跑 MPI 程序又担心受其他用户影响,通常有两种方式:
- 申请资源时,把资源的数量给到最大,比如 CPU 指定为 24 或 32;
- 申请资源时,资源数量任意,但加上参数
--exclusive指明申请的资源要被独占。
OpenMPI 的超额申请
OpenMPI 有一个 --oversubscribe 选项,该选项的作用和 Slurm 中的 oversubscribe 是类似的,都是在较少的硬件资源上执行较多的进程。MPICH 之类的实现则没有直接提供这个选项,而是默认开启 oversubscribe。
Slurm 实体的术语
参考:
Slurm 中有许多 entities(实体),它们通常都是对资源、任务的抽象,在 Slurm 运行时由守护进程管理。有关这些 entities 的资源比较分散,我们在此仅引用 Slurm 简介中的原文并做一点说明。
note
由于实验室只有一个集群,本节不对 cluster 等概念作说明。
原文如下:
The entities managed by these Slurm daemons, shown in Figure 2, include nodes, the compute resource in Slurm, partitions, which group nodes into logical (possibly overlapping) sets, jobs, or allocations of resources assigned to a user for a specified amount of time, and job steps, which are sets of (possibly parallel) tasks within a job. The partitions can be considered job queues, each of which has an assortment of constraints such as job size limit, job time limit, users permitted to use it, etc. Priority-ordered jobs are allocated nodes within a partition until the resources (nodes, processors, memory, etc.) within that partition are exhausted. Once a job is assigned a set of nodes, the user is able to initiate parallel work in the form of job steps in any configuration within the allocation. For instance, a single job step may be started that utilizes all nodes allocated to the job, or several job steps may independently use a portion of the allocation.
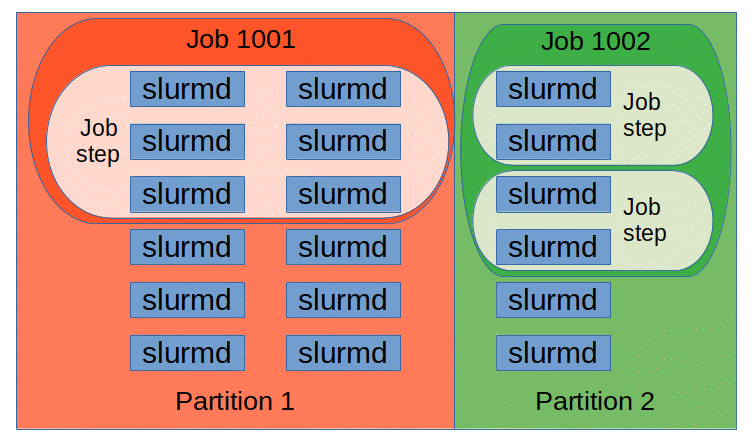
总的来说,一个分区可以包含多个作业,一个作业可以包含多个作业步,一个作业步可以使用多个节点,一个节点可以运行多个任务。
相关命令和参数
节点:常用参数为 -n、-w 和 -x,但通常不需要自己指定节点列表。
分区:常用参数为 -p,指定分区名称。
作业:常用命令为 salloc、sbatch 和 srun。
作业步:常用命令为 srun。
任务:常用参数为 -n 和 --ntasks-per-node。
节点(node)
节点是 Slurm 调度的单位之一,通常就是一个操作系统加一台机器(虚拟化技术得到的也算单个节点)。每个节点都有自己的资源,如 CPU、内存、GPU 等,这些资源也都是可调度的。
节点是由 Slurm 自动分配给作业的,通常只需要用户指定数量。但如果有特别的需要,用户也可以直接给定节点列表或者用参数排除一些节点。
分区(partition)
分区是 Slurm 组织节点的方式,在使用时相当于用户作业的队列。
分区就像给节点分组,便于批量操作。同一节点可以被编入多个不同分区,针对这种情况也可以调整优先级之类的设置。
作业(job)
作业指的是有时限的资源分配(resource allocation)。
用户提交一个作业,意味着要求 Slurm 分配一定量的资源让用户使用一定的时间;作业通过申请并开始执行,意味着 Slurm 已经分配了资源,用户可以开始执行自己的程序了。作业结束,意味着 Slurm 要回收资源并终止用户正在运行的程序。
如果用户使用脚本来提交作业,那么这个作业开始时会在被分配的第一个节点上执行这个脚本。环境变量默认会被广播到其他节点,因此用户使用 spack load 或 module load 加载的环境通常不会有什么问题。
作业步(job step)
指的是作业内的一些具体任务、程序的执行等。
前面所说的作业,表示的只是资源的使用权或者资源的分配(allocation),用户不一定会立刻运行并行程序。当用户使用 srun 或 mpirun 等命令执行并行程序时,Slurm 会认为这是一个作业步。
作业和作业步也可以通过编号来区分:作业步的编号形如 jobid.jobstep,比如 31001.0 就是作业 31001 的第一个作业步。
PMI
MPI 的安装通常要加上 Slurm 支持的进程管理接口(Process-Management Interface, PMI),否则 mpirun 可能无法正常使用。
任务(task)
指的是用户的一个任务,或者执行的一个程序。Slurm 中的 task 其实对应于 Linux 进程,不过它们一个属于 Slurm 的概念,一个是操作系统的概念。
一个并行程序通常都会有大量进程,此时就需要申请大量的 task。如果每个进程还使用了多线程编程模型(如 OpenMP),用户还应该为各线程留好计算资源。通常我们只需要让 task 数量等于所需的进程数量,让 CPU 数量等于所需的线程数量。
例如,在节点只有 24 CPUs 时运行 MPI+OpenMP 程序。若 MPI 进程为 1,线程数量是 24,我们可以申请 1 task,并要求每 task 包含 24 CPUs。
习惯用语
由于 task 实际上对应了进程,CPU 可以对应于线程,在平时讨论、各文档甚至文献中我们经常能见到混用 task/process 和混用 thread/CPU 的情况。